
Intelligence artificielle et désinformation
Intelligence artificielle et désinformation

Outils utiles
Il y a souvent un adage parmi les chercheurs et les scientifiques du monde entier: « sans données, tu n’es qu’une autre personne avec une opinion ». Cette phrase résume parfaitement l’élément fondamental de toute vérification d’une information ou d’une hypothèse: la comparaison avec la réalité. En fait, les données ne sont pas un ensemble de chiffres quelque peu aléatoires à interpréter, mais elles représentent plutôt de manière synthétique la réalité qui nous entoure.
C’est pour cette raison que le monde de l’information utilise largement les données, lesquelles nous permettent de connaître les tendances par rapport à un sujet spécifique, aident à supporter les convictions exprimées dans un article ou elle sont utilisées pour tester la véracité des déclarations d’hommes politiques ou de personnalités publiques. Cependant, ces données sont souvent utilisées de manière inappropriée. Parfois de bonne foi, parfois en maintenant une certaine ambiguïté pour corroborer ses propres thèses et, d’autres fois, avec l’intention déclarée de diffuser de fausses informations.
Dans cet article nous essayons de regrouper certains des éléments les plus importants à prendre en considération lors du traitement des données et des graphiques, à la fois pour mieux apprécier leurs qualités et leur capacité à représenter de manière simple des phénomènes très complexes, et pour éviter que quelqu’un essaie de nous tromper en nous racontant les faits de manière inappropriée.
Les statistiques peuvent être collectées et représentées de mille manières différentes. L’une des distinctions les plus importantes concerne la différence entre les statistiques quantitatives, c’est-à-dire mesurables par des chiffres (par exemple: la quantité de voitures vendues en Italie au cours de la dernière année), et les statistiques qualitatives, c’est-à-dire liées à la qualité ou à une caractéristique spécifique attribuée à un phénomène (par exemple: les sondages d’opinion qu’on conduit au sein de l’Union européenne, ce qu’on appelle l’Eurobaromètre).
Les statistiques quantitatives sont les plus utilisées dans le domaine de l’information et de la recherche et, à cause de leurs caractéristiques, elles sont aussi celles qui se prêtent le plus facilement à la manipulation. Cependant, beaucoup des principes que nous examinerons sont applicables aux deux types.
Choisir le bon échantillon
Le premier élément à prendre en considération est la représentativité de la statistique à laquelle nous sommes confrontés. L’objectif de la collecte de données est en effet de se rapprocher le plus possible de la description du phénomène étudié. Par exemple, si nous voulons connaître le nombre de personnes qui travaillent dans notre Pays, la meilleure façon de le faire est de frapper à chaque porte de ce Pays et de demander. Toutefois, une interview à si grande échelle entraînerait des coûts énormes. Il faudrait employer des dizaines de milliers d’enquêteurs qui devraient rencontrer des milliers de personnes en voyageant à travers toute l’Italie.
Les statistiques nous permettent cependant de surmonter en partie cette difficulté, grâce à l’analyse d’échantillons. En recourant aux outils et aux calculs mathématiques utilisés en statistique, il est en effet possible d’estimer avec une certaine précision l’ampleur d’un phénomène qui concerne la population en générale, et cela en analysant seulement une petite fraction de la population: un échantillon justement.
Cet échantillon ne peut cependant pas être tiré au hasard, mais doit être représentatif de la population: si, par exemple, nous voulons connaître l’opinion politique des Italiens, nous devrons avoir un échantillon composé environ pour une moitié d’hommes et pour l’autre moitié de femmes, de différentes classes d’âge proportionnellement au nombre de jeunes, d’adultes et de personnes âgées effectivement présents dans notre pays, provenant de différentes régions en fonction de leur poids dans la population, etc.
Si un échantillon est suffisamment représentatif, il suffit d’interviewer quelques personnes pour obtenir des résultats très précis. Il arrive assez souvent, par exemple, que pour les sondages politiques nationaux, qui tentent d’évaluer les choix de dizaines de millions d’électeurs, on considère grosso modo un millier de personnes interrogées.
Toutefois, si l’échantillon perd en représentativité, le nombre de réponses collectées doit augmenter significativement. Cela parce que une erreur dans la sélection de l’échantillon pourrait fausser considérablement les résultats offerts par les données collectées. Par exemple, si nous publiions une enquête sur les intentions de vote à partir du profil Instagram d’un secrétaire de parti, nous obtiendrions probablement un résultat écrasant en faveur de cette force politique. Même si nous obtenions des réponses de centaines de milliers de personnes, il s’agirait pour la plupart de personnes ayant des opinions politiques similaires à celles de la page sur laquelle on a publié l’enquête.
C’est ce qu’on appelle le biais de sélection, c’est-à-dire l’erreur qui se produit lorsqu’un échantillon représentatif de la population que l’on veut analyser n’est pas correctement sélectionné, car nous choisissons des sujets présentant des caractéristiques communes et qui les distinguent du reste de la société.
Le biais de sélection se produit non seulement lorsque ceux qui effectuent la recherche sélectionnent d’une façon erronée les personnes, mais également lorsque les personnes décident de participer, ou non, en fonction de leurs propres caractéristiques. Par exemple, si nous décidons de réaliser une enquête en ligne sur l’intérêt des gens pour l’escalade sportive, il est probable que quasi seulement les personnes intéressées par ce sport vont répondre. Après tout, passeriez-vous dix minutes de votre temps à répondre à des questions sur quelque chose dont vous ne savez rien et qui ne vous intéresse pas ?
Il existe également un phénomène de plus en plus courant des personnes qui choisissent de ne pas participer à l’entretien, ou de mentir lors d’un entretien, pour des raisons politiques. On en a beaucoup parlé pendant les élections américaines de 2016, lorsque les sondages avaient largement sous-estimé les préférences pour Donald Trump, qui a finalement remporté les élections. Ces erreurs étaient probablement dues au fait que les électeurs de Trump, notoirement plus sceptiques à l’égard des institutions, ont eu un taux de réponse plus faible. Probablement, alors qu’elles ont répondu au téléphone et elles ont entendu à l’autre bout du fil une société de sondage, perçue comme faisant partie de l’establishment, ces personnes étaient plus susceptibles de ne pas perdre de temps à répondre aux questions. Par conséquent les instituts de sondage ont construit des échantillons théoriquement représentatifs de l’électorat, avec une part de républicains conforme à la population générale, mais en interrogeant principalement des républicains plus modérés et en sous-estimant le rôle de la partie la plus extrémiste de l’électorat du parti.
La moyenne et la médiane
Un autre concept fondamental pour mieux interpréter les chiffres est celui de moyenne. Lorsque l’on pense à la moyenne arithmétique, c’est-à-dire la somme de toutes les données soumises à notre analyse, divisée par la taille de l’échantillon analysé, nous tenons souvent pour acquis que le résultat de ce calcul montre un résultat plutôt représentatif de la population.
Par exemple, si nous savons que dans une ville de dix habitants le revenu moyen est de 100 mille euros, nous avons tendance à croire que si nous demandions à l’un de ces citoyens combien il gagne, il nous répondrait avec un chiffre proche de 100 mille euros, c’est-à-dire autour de la moyenne prévue. Mais il n’est pas du tout évident que la majorité des citoyens soient proches de cette valeur. Par exemple, neuf habitants sur dix pourraient travailler au Smic et gagner mille euros chacun, tandis qu’un seul habitant pourrait gagner 991 mille euros. La moyenne, égale à 991 mille + 9 mille (mille euros pour neuf travailleurs), soit la somme de tous les salaires du pays, puis divisée par dix (le nombre d’habitants du pays), donne 100 mille euros de revenu par habitant, mais la manière dont cet argent est distribué est très différente.
Cet exemple extrême nous aide à comprendre le premier défaut de la moyenne: d’une part, c’est un indicateur extrêmement synthétique, car avec un seul chiffre il peut nous donner beaucoup d’informations utiles, telles une mesure indicative du revenu d’un pays, d’autre part, cette synthèse réduit la représentativité de l’indicateur. En fait, un seul chiffre ne peut résumer complètement une situation aussi particulière que celle que nous avons vue dans l’exemple ci-dessus.
Toutefois, même dans des cas moins extrêmes, la moyenne peut être trompeuse. La raison est due généralement à la présence de outlier, c’est-à-dire de données collectées qui ont une valeur extrême, comme notre millionnaire dans le village de dix habitants dans l’exemple ci-dessus. Le revenu est l’un des cas les plus connus où il faut faire attention à la moyenne. Cela parce que les revenus sont généralement répartis de manière très spécifique: la majorité de la population a tendance à avoir un revenu modeste (faible à moyen), tandis qu’une minorité gagne, proportionnellement, beaucoup plus que la « classe moyenne ». La présence de ces revenus très élevés fait augmenter considérablement la moyenne, nous donnant l’idée que la population en général gagne plus qu’elle ne gagne réellement.
Savoir interpréter au mieux cet indicateur est également fondamental pour le monde de l’information: en effet, il n’est pas rare que les données sur le revenu moyen soient présentées comme représentatives de la « classe moyenne ». Le spectateur ou le lecteur, qui a généralement tendance à s’identifier à la classe moyenne, lisant ces données ou les écoutant à la télévision pourrait ressentir de la colère ou de la déception en découvrant qu’il gagne moins que la moyenne, tenant pour acquis que ces données correspondent à sa “classe sociale de référence”. Mais, comme nous venons de le dire, les chiffres exprimés sont en réalité souvent surestimés.
Comment alors comprendre comment se porte la classe moyenne? En utilisant la médiane, un indicateur qui divise la population en deux: la moitié est au-dessus de cette valeur, l’autre moitié est en dessous. Si, par exemple, le revenu médian d’un village de dix habitants vaut 50 mille euros, cela signifie que cinq habitants gagnent plus de 50 mille euros et cinq habitants moins. Dans l’exemple que nous avons donné précédemment, le revenu moyen était de 100 mille euros, avec neuf personnes qui gagnent mille euros et une qui gagne 991 mile euros. Le revenu médian vaudrait plutôt mille euros (dans ce cas, plutôt que d’être inférieur ou supérieur, neuf données sur dix sont égales à la valeur médiane).
Cette différence se voit également dans les données italiennes: en moyenne, les salariés gagnaient 14,79 euros de l’heure en 2021, soit environ 2 366 euros bruts pour un travailleur à temps plein; si l’on regarde la médiane, cependant, le chiffre tombe à 11,69 euros de l’heure, soit 1 870 euros bruts par mois, un chiffre nettement plus conforme à la perception du salaire de la majorité de la population de notre pays. Pour rendre notre analyse encore plus complète, on peut également considérer différents seuils en plus de la médiane: par exemple, on peut se demander combien gagnent le 10 % le plus riche ou le 10 % le plus pauvre.
Mieux comprendre les concepts de représentativité des échantillons et de moyenne est déjà un outil important pour interpréter les données, mais il y a beaucoup de choses à apprendre autour de l’analyse des statistiques. Pour apprendre les méthodes statistiques les plus avancées avec une approche très informative, une ressource très utile est masteringmetrics.com (en anglais), édité par le prix Nobel d’économie 2021 Joshua Angrist.
Comment ne pas se laisser tromper par les graphiques
L’un des outils les plus pratiques pour la communication des données, et donc aussi pour les représenter de manière trompeuse si on ne l’utilise pas correctement, est la data visualisation, c’est-à-dire la création d’infographies qui représentent les données de manière visuelle et immédiate.
Ces infographies peuvent se limiter à de simples graphiques, tels que l’évolution des dépenses de santé dans le temps représentée par une ligne, ou elles peuvent être des œuvres véritablement complexes, dans lesquelles la visualisation contribue à simplifier la compréhension des données, comme dans cette représentation des flux de revenus de Apple.
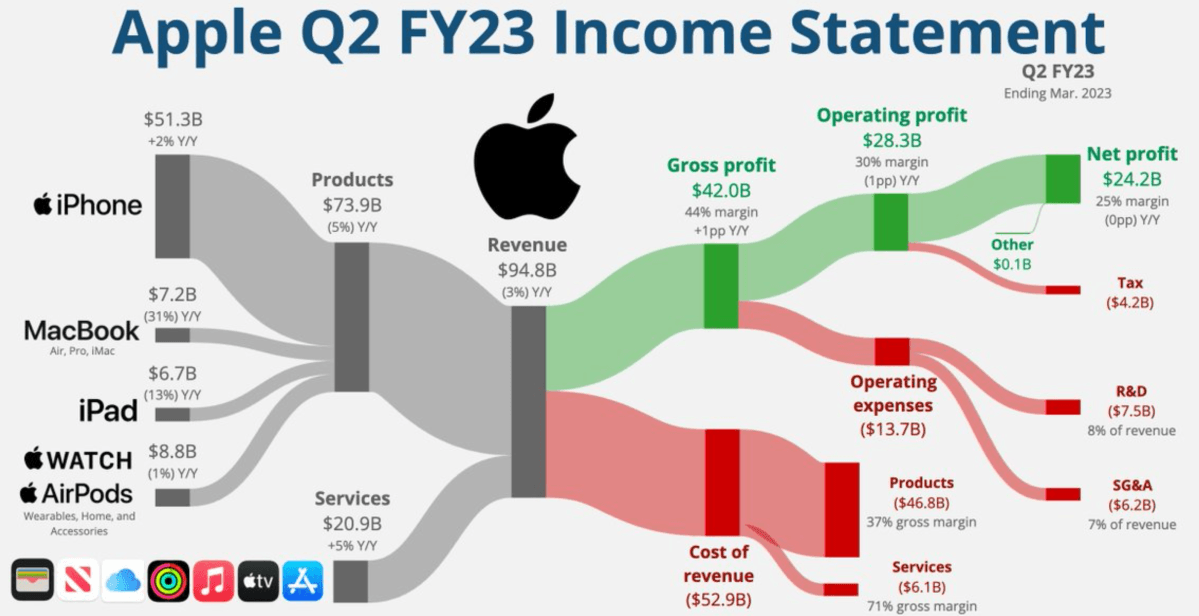
Bien que le niveau de complexité des deux graphiques ci-dessus soit très différent, dans les deux cas l’utilisation de la graphique a considérablement réduit cette complexité. Dans le cas des dépenses de santé, au lieu d’utiliser un tableau montrant toutes les valeurs année par année, il suffit généralement de montrer comment les données évoluent dans le temps, à l’aide d’une simple ligne. Cependant, dans le cas des revenus d’Apple, au lieu d’un bilan complet, nous nous retrouvons à lire une seule infographie contenant presque toutes les informations dont nous avons besoin.
Même avec les infographies, il est possible de mentir. Non seulement en indiquant des données erronées, mais aussi en les représentant de manière incorrecte. Pour éviter toutes les astuces possibles qui rendent une représentation trompeuse, il faut beaucoup d’études et d’expérience, mais il existe aussi des méthodes souvent utilisées dans le monde de l’information et qui sont assez simples à reconnaître. Voyons quelques exemples.
Un cas toujours cité est celui des histogrammes, c’est-à-dire les graphiques à colonnes que l’on voit si souvent dans les articles et les reportages télévisés. Pour montrer les différences, il arrive que l’on décide de couper l’axe vertical, comme cela a été fait dans ce graphique sur les intentions de vote pour le référendum sur le Brexit.
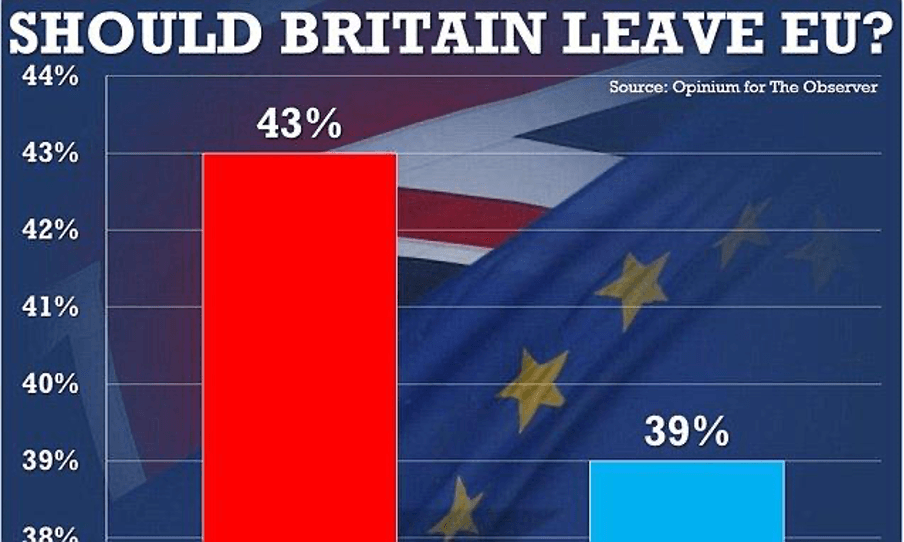
Dans ce cas, il semble que la majorité des citoyens britanniques souhaitait quitter l’UE, ce qui est en partie vrai, car il s’agit du groupe le plus nombreux. Mais aussi que, en même temps, presque personne ne voulait rester à l’intérieur de l’UE. Cependant, la lutte a été beaucoup plus serrée que prévu: Leave and Remain (Partir et Rester) n’étaient en fait séparés que de 4 points de pourcentage.
Le fait d’avoir tellement agrandi la dernière section de l’histogramme, montrant cette différence comme si elle était infranchissable, a un impact fort: d’une part, cela pourrait pousser les partisans du remain (rester) à aller voter pour combler la différence, mais cela pourrait aussi les démotiver et les poussez à rester chez eux, car ces chiffres les portent à penser que la partie est déjà perdue. Changer la taille de l’axe Y (l’axe vertical) est plus que légitime et permet souvent de mettre les choses dans une perspective meilleure. Toutefois, il est important de vérifier quel effet on obtient avec cet agrandissement: celui qui l’a fait, voulait-il nous faire mieux comprendre le phénomène ou essayer de montrer les données dans une perspective non objective?
Une utilisation faussée de l’axe vertical ne concerne pas seulement les graphiques à barres, mais également les lignes. Les deux graphiques ci-dessous, par exemple, montrent les mêmes données, mais le message qui en sort est différent: dans le premier cas, il semble que l’industrie italienne se soit complètement arrêtée en correspondance de la chute, tandis que dans le second cette perspective est plus limitée. Dans les deux cas, si l’on considère que la baisse a été de 20 pour cent, la représentation est peut-être un peu extrême. Un bon compromis pourrait être de fixer le minimum de l’axe Y à 50.
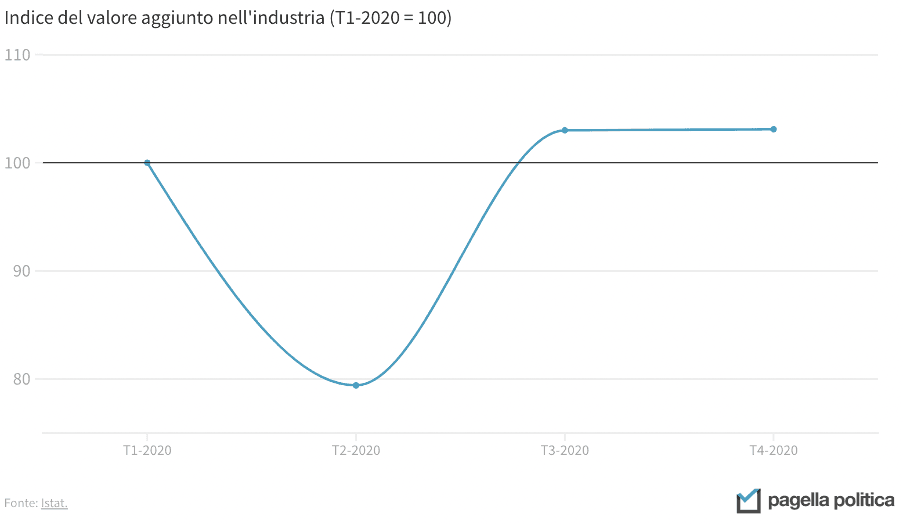
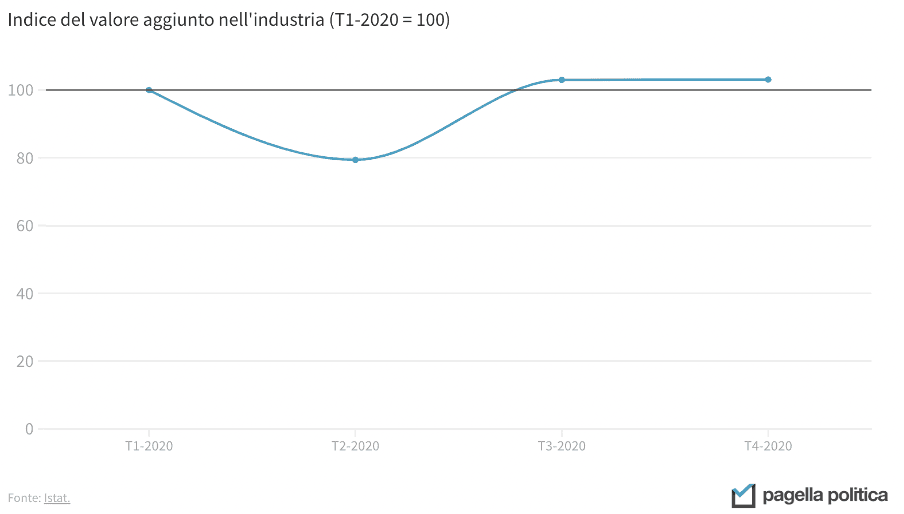
Les données et les infographies sont à la base du travail de nombreux journalistes, des décideurs et, bien sûr, des scientifiques et des analystes. Mieux en comprendre le potentiel et apprendre à les interpréter correctement est la clé pour mieux lire la réalité qui nous entoure. De plus, les données sont fondamentales pour évaluer l’impact des politiques qui veulent changer cette réalité, nous aidant à comprendre si elles ont été efficaces et où elles peuvent s’améliorer. Sans une confrontation constante à la réalité grâce aux données, il est impossible d’être véritablement informés. Parce que sans données, nous ne sommes que “une autre personne avec une opinion”.
