Geolocalizzazione di un contenuto
Geolocalizzazione di un contenuto

Strumenti utili
Tra ricercatori e scienziati di tutto il mondo gira spesso un detto: “senza dati, sei solo un’altra persona con un’opinione”. Questa frase riassume perfettamente l’elemento fondamentale di ogni verifica di un’informazione o di un’ipotesi: il confronto con la realtà. I dati non sono infatti un insieme un po’ casuale di numeri da interpretare, ma rappresentano in maniera sintetica la realtà che ci circonda.
Per questo motivo, il mondo dell’informazione fa largo uso dei dati, che permettono di raccontare le tendenze rispetto a un determinato tema, aiutano a sostenere le convinzioni espresse all’interno di un articolo o vengono utilizzati per testare la veridicità delle dichiarazioni di politici o personaggi pubblici. Spesso, però, questi dati vengono utilizzati in maniera impropria. A volte in buona fede, a volte mantenendo una certa ambiguità per sostenere le proprie tesi e, a altre volte, con l’intenzione dichiarata di diffondere fake news.
In questo articolo proviamo a mettere in fila alcuni degli elementi più importanti da tenere in considerazione quando si ha a che fare con dati e grafici, sia per apprezzarne al meglio le qualità e la capacità di rappresentare in modo semplice fenomeni molto complessi, sia per evitare che qualcuno provi a trarci in inganno raccontandoceli in modo improprio.
Le statistiche possono essere raccolte e rappresentate in mille modi diversi. Una delle più importanti distinzioni riguarda la differenza tra statistiche quantitative, misurabili cioè attraverso numeri (ad esempio: la quantità di auto vendute in Italia nell’ultimo anno), e statistiche qualitative, ossia legate alla qualità o a una caratteristica specifica che si attribuisce a un fenomeno (ad esempio: i sondaggi di opinione che si svolgono all’interno dell’Unione europea, il cosiddetto Eurobarometro).
Le statistiche quantitative sono quelle più utilizzate nell’ambito dell’informazione e della ricerca e, per le loro caratteristiche, sono anche quelle che si prestano più facilmente a essere manipolate. Molti dei principi che andremo a vedere, però, sono applicabili a entrambi i tipi.
Scegliere il campione giusto
Il primo elemento da tenere in considerazione è la rappresentatività della statistica che ci troviamo davanti. L’obiettivo della raccolta dati, infatti, è quello di avvicinarsi il più possibile a descrivere il fenomeno che si sta studiando. Per esempio, se vogliamo conoscere il numero di persone che lavorano nel nostro paese, il modo migliore per farlo è bussare a ogni casa in tutta la Penisola e chiedere. Un’intervista su così ampia scala, però, avrebbe costi enormi. Bisognerebbe impegnare decine di migliaia di intervistatori che dovrebbero incontrare migliaia di persone viaggiando per tutto il paese.
La statistica, però, ci permette di superare in parte questa difficoltà, grazie all’analisi campionaria. Facendo ricorso agli strumenti e ai calcoli matematici utilizzati in statistica, infatti, è possibile stimare con una certa precisione la portata di un fenomeno che riguarda la popolazione generale, andando ad analizzarne solo una piccola frazione: un campione, appunto.
Questo campione, però, non può essere preso a caso, ma deve essere rappresentativo della popolazione: se, per esempio, vogliamo conoscere l’opinione politica degli italiani, dovremo avere un campione composto per circa metà da uomini e metà da donne, di diverse classi di età in proporzione al numero di giovani, adulti e anziani effettivamente presenti nel nostro paese, provenienti da diverse regioni in base al loro peso sulla popolazione e così via.
Se un campione è rappresentativo a sufficienza, bastano anche solo poche persone intervistate per ottenere risultati molto precisi. Non è raro, per esempio, che per i sondaggi politici nazionali, che provano a stimare le scelte di decine di milioni di elettori, si faccia riferimento a un migliaio di intervistati o poco più.
Se però il campione perde di rappresentatività, il numero di risposte raccolte deve crescere di molto. Questo perché un errore nella selezione del campione potrebbe distorcere in maniera decisiva i risultati offerti dai dati raccolti. Se per esempio pubblicassimo un sondaggio sulle intenzioni di voto dal profilo Instagram di un segretario di partito, otterremmo probabilmente un risultato schiacciante a favore di quella forza politica. Anche se ottenessimo le risposte di centinaia di migliaia di persone, si tratterebbe per lo più di persone che hanno idee politiche affini a quelle della pagina che ha pubblicato il sondaggio.
Si tratta del cosiddetto bias di selezione, cioè l’errore che si commette quando non si seleziona in maniera corretta un campione rappresentativo della popolazione che si vuole analizzare, ma si vanno a pescare soggetti con caratteristiche comuni e che li distinguono dal resto della società.
Il bias di selezione non si ha solo quando chi svolge la ricerca seleziona in modo sbagliato le persone, ma anche quando le persone decidono di partecipare o meno in base a proprie caratteristiche. Per esempio, se decidiamo di svolgere un sondaggio online sull’interesse delle persone per l’arrampicata sportiva, è probabile che risponderanno quasi solo individui che si interessano a quello sport. Del resto, voi spendereste dieci minuti del vostro tempo per rispondere a domande su qualcosa di cui non sapete e non vi interessa nulla?
C’è poi anche un fenomeno sempre più comune di persone che scelgono di non partecipare o di mentire all’intervista per motivazioni politiche. Se ne era parlato molto durante le elezioni statunitensi del 2016, quando i sondaggi sottostimarono di molto le preferenze per Donald Trump, che poi vinse le elezioni. Gli errori furono dovuti probabilmente al fatto che gli elettori di Trump, notoriamente più scettici nei confronti delle istituzioni, avevano un tasso di risposta più basso. Probabilmente, rispondendo al telefono e sentendo dall’altro capo della cornetta una società di sondaggi, percepita come parte dell’establishment, queste persone erano più propense a non perdere tempo per rispondere alle domande. Questo ha fatto sì che gli istituti di sondaggi costruirono campioni in teoria rappresentativi dell’elettorato, con una quota di repubblicani in linea con la popolazione generale, ma andando a intervistare soprattutto repubblicani più moderati e sottostimando il ruolo della parte più estremista dell’elettorato del partito.
Media e mediana
Un altro concetto fondamentale per interpretare al meglio i numeri è quello di media. Quando pensiamo alla media aritmetica, ossia la somma di tutti i dati oggetto della nostra analisi divisa per la numerosità del campione analizzato, spesso diamo per scontato che il risultato di quel calcolo mostri un risultato piuttosto rappresentativo della popolazione.
Per esempio, se sappiamo che in un paese di dieci abitanti il reddito medio è di 100 mila euro, ci viene da pensare che, se fermassimo uno di questi cittadini e chiedessimo quanto guadagna, ci risponderebbe una cifra intorno a quei 100 mila euro di media. Ma non è per niente scontato che la maggior parte dei cittadini sia vicina a quel valore. Per esempio, nove dei dieci abitanti potrebbero lavorare a salario minimo, guadagnando mille euro ognuno, mentre un solo abitante potrebbe guadagnare 991 mila euro. La media, pari a 991 mila + 9 mila (mille euro per nove lavoratori), ossia la somma di tutti i salari del paese, divisi poi per dieci (il numero di abitanti del paese), porta sì a 100 mila euro di reddito per ciascun abitante, ma il modo in cui questo denaro è distribuito è ben diverso.
Questo esempio estremo ci aiuta a capire il primo difetto della media: da una parte, è un indicatore estremamente sintetico, perché con un solo numero riesce a darci molte informazioni utili, come per esempio una misura indicativa del reddito di un paese, dall’altra, però, questa sintesi riduce la rappresentatività dell’indicatore. Un solo numero non può infatti sintetizzare in maniera completa una situazione così particolare come quella che abbiamo visto nell’esempio sopra.
Anche in casi meno estremi, comunque, la media può essere fuorviante. Il motivo è di solito la presenza di outlier, ossia dati raccolti che hanno un valore estremo, come il nostro milionario nel paesino di dieci persone nell’esempio di prima. Il reddito è uno dei casi più noti in cui bisogna fare attenzione alla media. Questo perché i redditi sono di solito distribuiti in un modo ben preciso: la maggioranza della popolazione tende ad avere un reddito medio-basso, mentre una minoranza guadagna molto di più, in proporzione, rispetto alla “classe media”. La presenza di questi redditi molto alti alza di parecchio la media, dandoci l’impressione che la popolazione generale guadagni più rispetto a quanto faccia effettivamente.
Saper interpretare al meglio questo indicatore è fondamentale anche per il mondo dell’informazione: non è infatti per niente raro che il dato sul reddito medio venga presentato come rappresentativo della “classe media”. Lo spettatore o il lettore, che di solito tende a identificarsi proprio con la classe media, leggendo o ascoltando in televisione questo dato potrebbe provare rabbia o delusione nello scoprire di guadagnare meno della media, dando per scontato che quello sia il dato per la sua “classe sociale di riferimento”. Come abbiamo visto, però, è in realtà spesso sovrastimato.
Come facciamo allora a capire come sta la classe media? Utilizzando la mediana, un indicatore che divide in due la popolazione: metà sta al di sopra di quel valore, l’altra metà sta al di sotto. Se, per esempio, il reddito mediano di un paese di dieci abitanti vale 50 mila euro, significa che cinque abitanti guadagnano più di 50 mila euro e cinque abitanti meno. Nell’esempio che avevamo fatto prima, il reddito medio era di 100 mila euro, con nove persone che guadagnano mille euro e una che ne guadagna 991 mila. Il reddito mediano varrebbe invece mille euro (in questo caso, anziché stare al di sotto o al di sopra, nove dati su dieci risultano pari al valore mediano).
Questa differenza la si vede anche nei dati italiani: in media, i lavoratori dipendenti guadagnavano 14,79 euro l’ora nel 2021, circa 2.366 euro lordi per un lavoratore full time; se andiamo a vedere la mediana, però, il dato scende a 11,69 euro l’ora, pari a 1.870 euro lordi al mese, un dato decisamente più in linea con quello che è la percezione delle retribuzioni per la maggior parte della popolazione nel nostro paese. Per rendere ancora più completa la nostra analisi, possiamo considerare anche diverse soglie oltre alla mediana: per esempio, possiamo chiederci quanto guadagna il 10 per cento più ricco o il 10 per cento più povero.
Comprendere al meglio i concetti di rappresentatività del campione e di media è già uno strumento importante per interpretare i dati, ma le cose da imparare riguardo all’analisi delle statistiche sono moltissime. Per imparare con un taglio molto divulgativo i metodi statistici più avanzati una risorsa molto utile è masteringmetrics.com (in inglese), curato dal Premio Nobel per l’Economia 2021 Joshua Angrist.
Come non farsi ingannare dai grafici
Uno degli strumenti più utili per divulgare i dati, e quindi anche per rappresentarli in modo fuorviante se non si utilizza correttamente, è la data visualisation, ossia la creazione di infografiche che rappresentino i dati in maniera visiva e immediata.
Queste infografiche possono limitarsi a semplici grafici, come l’andamento della spesa sanitaria nel tempo rappresentato da una linea, o essere vere e proprie opere complesse, in cui la visualizzazione aiuta a semplificare la comprensione del dato, come in questa rappresentazione dei flussi dei ricavi di Apple.
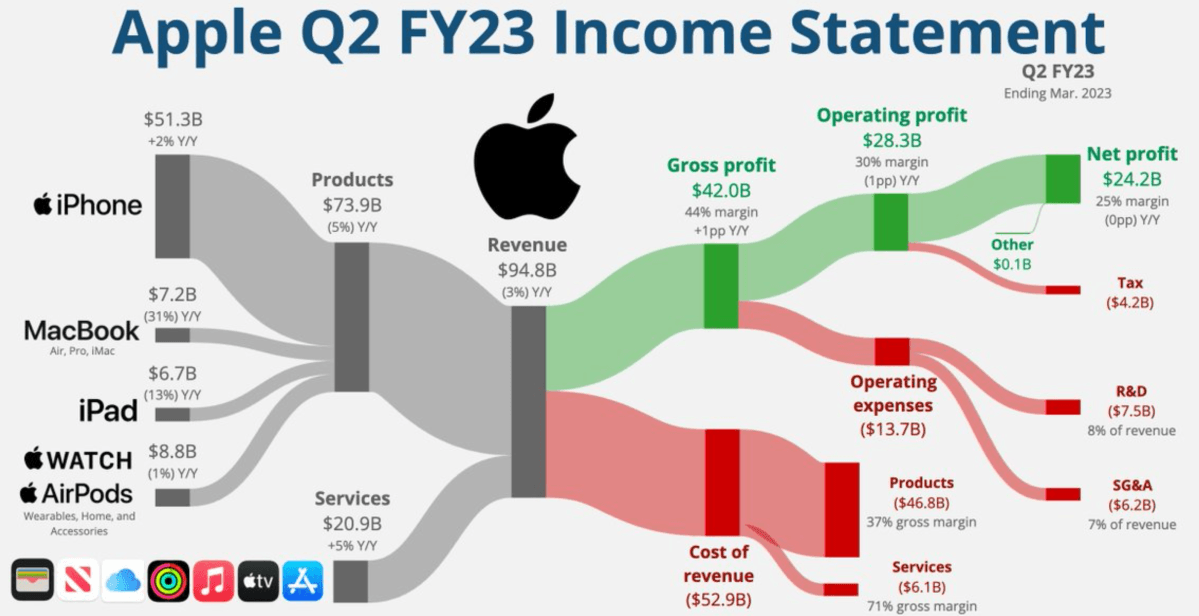
Sebbene il livello di complessità delle due grafiche qui sopra sia molto diverso, in entrambi i casi l’utilizzo della grafica ha ridotto di molto questa complessità. Nel caso della spesa sanitaria, anziché con una tabella che riporti tutti i valori anno per anno, basta di solito mostrare come cambia il dato nel tempo, tramite una semplice linea. Nel caso dei ricavi di Apple, invece, anziché un intero bilancio, ci troviamo a leggere una singola infografica che riporta quasi tutte le informazioni di cui si ha bisogno.
Anche con le infografiche è possibile mentire. Non solo riportando dati sbagliati, ma anche rappresentandoli in modo scorretto. Per evitare tutti i possibili trucchi che rendono una rappresentazione fuorviante servono molto studio e molta esperienza, ma esistono alcuni metodi che vengono spesso utilizzati nel mondo dell’informazione e che sono abbastanza semplici da riconoscere. Vediamo un paio di esempi.
Un caso che viene sempre citato è quello degli istogrammi, ossia i grafici a colonne che vediamo così spesso su articoli e servizi in televisione. Per mostrare le differenze, accade che si decida di tagliare l’asse verticale, come è stato fatto in questo grafico sulle intenzioni di voto per il referendum sulla Brexit.
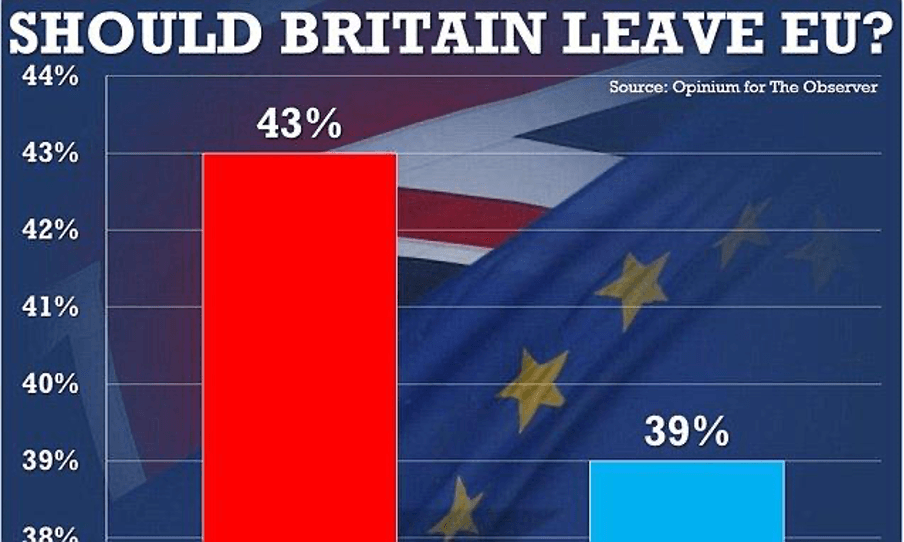
In questo caso, sembra che la maggior parte dei cittadini del Regno Unito volesse uscire dall’Ue, che è in parte vero, trattandosi del gruppo più numeroso. Ma anche che, allo stesso tempo, quasi nessuno volesse rimanervi dentro. E invece la lotta era molto più serrata del previsto: il leave e il remain erano infatti separati da soli 4 punti percentuali.
Aver ingrandito così tanto la sezione finale dell’istogramma, mostrando questa differenza come se fosse incolmabile, ha un forte impatto: da una parte, potrebbe spingere i favorevoli al remain ad andare a votare per colmare il gap, ma potrebbe anche demotivarli e spingerli a rimanere a casa, perché portati a pensare che la partita sia già persa. Modificare la dimensione dell’asse Y (quello verticale) è più che legittimo e spesso aiuta davvero a mettere in una prospettiva migliore queste cose. È importante però verificare qual è l’effetto che si ottiene con questo ingrandimento: chi lo ha fatto voleva farci capire meglio il fenomeno o provare a mostrare i dati da una prospettiva di parte?
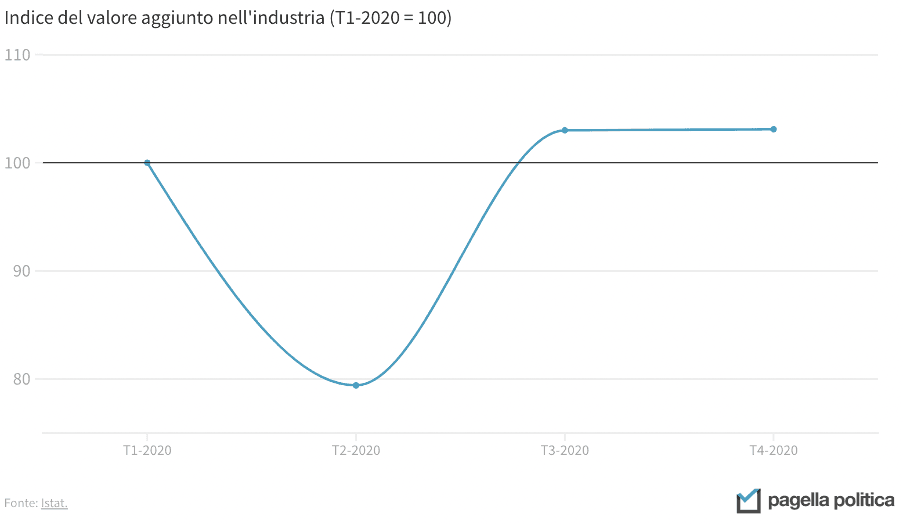
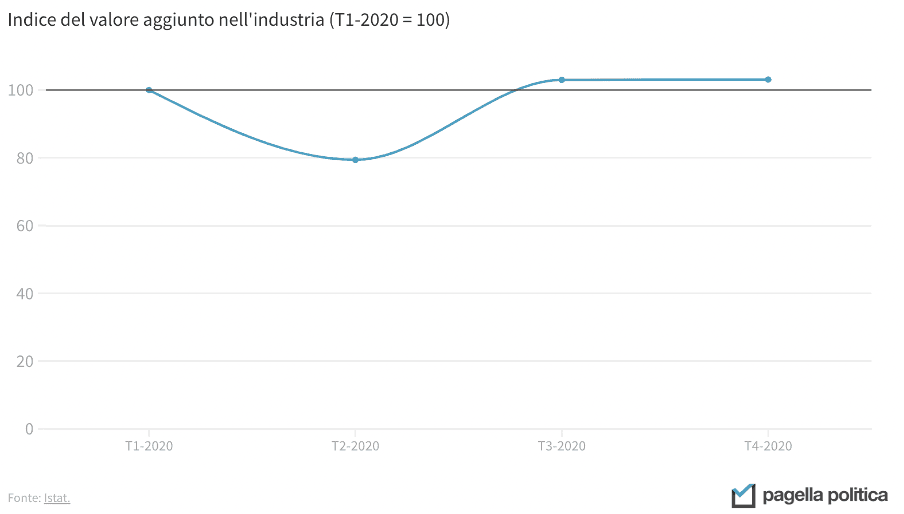
L’uso scorretto dell’asse verticale non riguarda solo i grafici a barre, ma anche le linee. I due grafici qui sotto, per esempio, mostrano lo stesso dato, ma il messaggio che arriva è diverso: nel primo caso, sembra che l’industria italiana si sia completamente fermata in corrispondenza del crollo, mentre nel secondo questa prospettiva risulta più contenuta. In entrambi i casi, considerando che il calo è stato del 20 per cento, la rappresentazione è forse un po’ estrema. Una buona via di mezzo potrebbe essere impostare a 50 il minimo della asse Y.
I dati e le infografiche sono alla base del lavoro di moltissimi giornalisti, policy maker e, naturalmente, scienziati e analisti. Comprenderne al meglio il potenziale e imparare ad interpretarli nel modo corretto è la chiave per capire al meglio la realtà che ci circonda. I dati sono poi fondamentali per valutare l’impatto delle politiche che quella realtà vogliono cambiarla, aiutandoci a capire se sono state efficaci e dove possono migliorare. Senza un controllo costante della realtà attraverso i dati, essere davvero informati è impossibile. Perché senza dati, sei solo un’altra persona con un’opinione.
